Fast Filtering of Load Balanced or Proxied Connections
A common problem exists when investigating network issues through packet analysis. Web scale architecture provides ways to distribute workloads, and those mechanisms tend to abstract away silly things like the 5-tuple frequently used to identify individual conversations. Both proxies and load balancers can obscure a client’s IP address and source TCP port, and that makes it difficult to isolate a specific conversation across multiple networking devices.
The goal of this post is to describe an automated way to see if traffic is making it past the proxy, which can be extended to isolate the 5-tuple for the part of the conversation behind the proxy (source IP, source port, destination IP, destination port, TCP/UDP).
Architecture for this Scenario
To demonstrate how this can happen, a simple sample architecture can be used that shows a basic load balanced website.
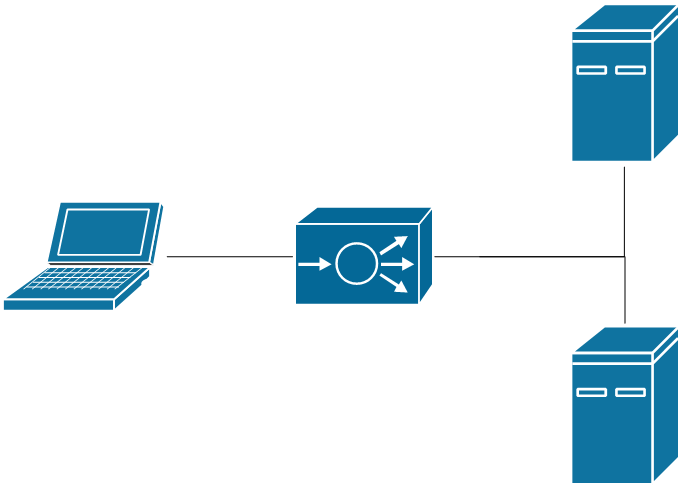
Sample architecture depicting a user, a load balancer, and a pair of web servers
This assumes a few configuration options:
- The client connects via HTTPS to the load balancer.
- The load balancer performs SSL offload and the traffic within the data center is unencrypted.
- The load balancer replaces the client's IP address with it's own Virtual IP Address (VIP).
These conditions typically mean that the load balancer will pass along a client's IP address within an X-Forwarded-For field within the HTTP header. This means that if we have firewall or load balancer logs that show incoming connections, or we have customers calling in who can give us their IP address, it is possible to isolate their traffic behind the load balancer.
Significance of a Novel Technique
If we can go through and find the traffic, why am I even writing this post?
Most packet analysis tools (including Wireshark, Endace, and some of the various Riverbed tools), are really good at quickly filtering through protocol headers because they’re optimized for parsing that binary data. They are less efficient at filtering through an ASCII-formatted HTTP header. Even Scapy, which is a Python library made for messing with packets, isn’t well optimized for looking through packet payloads.
Proposed Technique
For this task, it turns out that simplicity is key. To begin, we need a known client IP address and a broad packet capture behind the load balancer or proxy (it is really easy for a 5-10 minute packet capture to reach 100+ GB in an enterprise environment).
Step 1: Confirm the traffic exists
It doesn’t help to expend time and compute power searching through the details of a massive packet capture file if we don’t know the traffic under investigation even exists. I’ve found that the fastest way to do so is to ignore all the protocol headers. It takes time to process binary, especially if Scapy is doing it, so we can save a lot of time by reading in the PCAP as a regular text file.
To save on system memory (because I don’t have 100GB of RAM in my computer), we read line-by-line.
with open(pcap_fn, mode="rb") as pcap:
print "PCAP Loaded"
for line in pcap:
iterate_basic_ip_check(line,target_ip)In the HTTP header, the different fields are delimited by a newline character, so the X-Forwarded-For field we’re looking for appears in it’s own line using this technique, which allows us to match an ip address with some really simple regex.
def iterate_basic_ip_check(line, target):
match = re.match('X-Forwarded-For: (\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})',line)
if match:
if match.group(1) == target:
print "Target IP %s found" % targetAll put together, this script (available on Github) runs blazingly fast. I estimated 200+ MB/sec on my machine, and it’s possible to parallelize this workload to take advantage of multiple cores.
Step 2: Isolate the 5-tuple
Once we know the correct traffic exists, we can re-iterate using Scapy to identify the 5-tuple, or potentially multiple 5-tuples, used. This is left as an exercise for the reader (you can thank my engineering textbooks for teaching me this wonderful and horribly frustrating phrase).
Conclusion
If you find yourself in the position where an expected IP address is disappearing behind a proxy or load balancer, it is possible to process a fairly large amount of data to isolate the conversation in the next segment of the network as long as the HTTP header is exposed.

